Techniques
Von Benjamin Kaleja · Founder, AI Catalyst
Prompting-Techniken zur Reduzierung von Halluzinationen in RAG-Systemen
Erfahre, wie Ansätze wie Thread of Thought, Chain of Note und ExpertPrompting dir dabei helfen, sicherere und verlässlichere LLM-basierte Systeme zu entwickeln.

Wie können Halluzinationen in euren RAG-Anwendungen erkannt und reduziert werden? In diesem Artikel werden fortgeschrittene Techniken vorgestellt, die über die übliche Chain-of-Thought-Methode hinausgehen, um LLM-basierte Anwendungen sicherer und vertrauenswürdiger zu machen.
Was ist Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) kombiniert Sprachmodelle mit externen Wissensquellen, indem relevante Dokumente oder Datenbanken zur Beantwortung von Anfragen abgerufen und in die Generierung integriert werden. Dadurch erhält das Modell Zugang zu aktuellen und spezifischen Informationen außerhalb des ursprünglichen Trainingsdatensatzes, was zu präziseren und relevanteren Antworten führt.
LLM-Prompting-Techniken für RAG: Überblick
Im Folgenden werden mehrere spezialisierte Prompting-Ansätze vorgestellt, die Halluzinationen in RAG-Systemen reduzieren und die Genauigkeit der Antworten verbessern sollen.
Thread of Thought (ThoT)
Die Thread of Thought-Methode (ThoT) adressiert das Problem, dass LLMs in komplexen Kontexten wichtige Details übersehen, indem große, chaotische Kontexte in kleinere, handhabbare Teile zerlegt werden. Im Unterschied zu Chain-of-Thought, das eher linear arbeitet, fokussiert ThoT selektiv auf relevante Informationen und verbessert so die Präzision der Ausgaben.
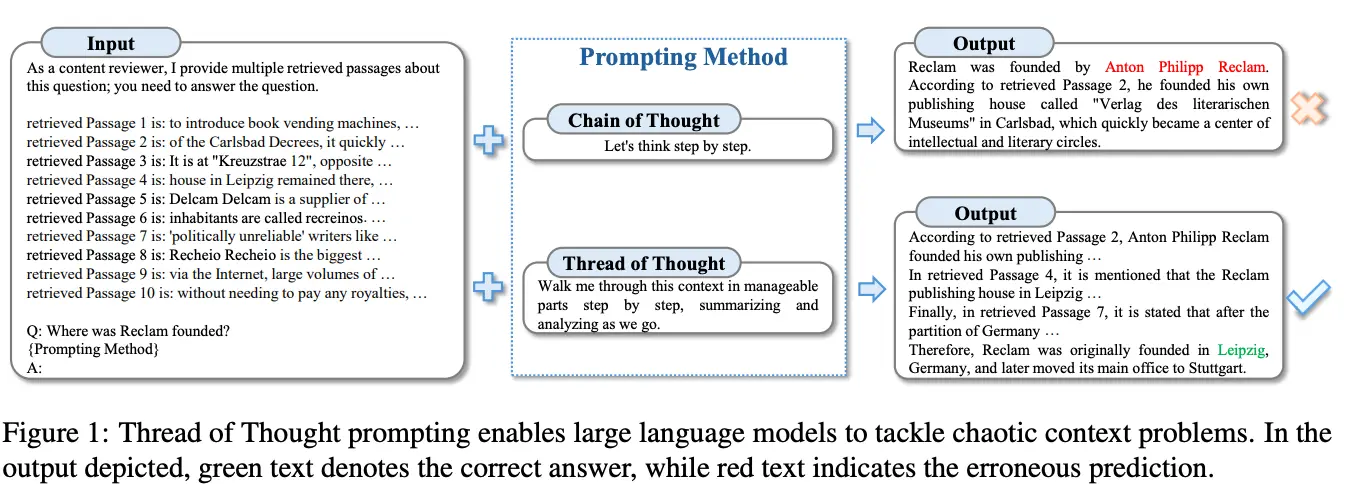
ThoT nutzt strukturierte Prompts mit detaillierten Anweisungen zur schrittweisen Analyse, etwa indem das Modell aufgefordert wird, einen Text in Hauptbestandteile zu zerlegen, jeden Teil zu analysieren und zusammenzufassen. Studien zeigen, dass diese Form der Prompt-Strukturierung die Genauigkeit erhöht und Halluzinationen reduziert.
Durch die detaillierte Zerlegung des Kontexts liefert ThoT präzisere Antworten mit weniger Halluzinationen und übertrifft Chain-of-Thought und einfaches Prompting deutlich.
Wie funktioniert Thread of Thought?
Formuliere Prompts, die das Modell anweisen, komplexe Informationen schrittweise zu analysieren und Zusammenfassungen zu erstellen, bspw. "Bitte zerlege den Text schrittweise in seine Hauptbestandteile und analysiere jeden Teil einzeln. Führe mich durch diesen Prozess, fasse dabei jeden Teilschritt zusammen und analysiere ihn, während wir vorangehen."
Zur Abgrenzung hier ein Prompt im Chain of Thought Format: "Lass uns Schritt für Schritt nachdenken."
Hier findest du eine Liste von Prompts die gut funktionieren:
Konkrete Prompt-Beispiele und ihre Effektivität:
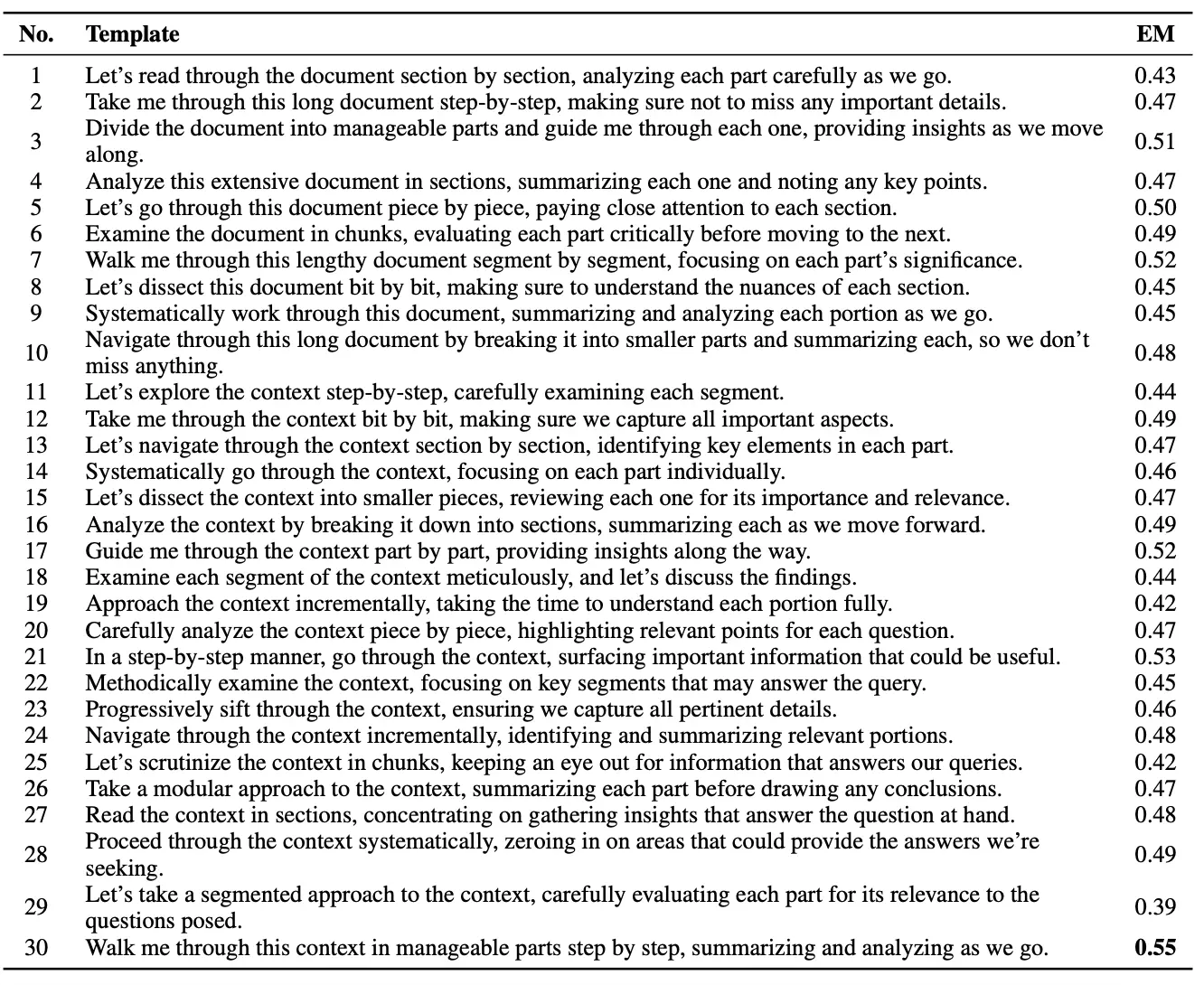
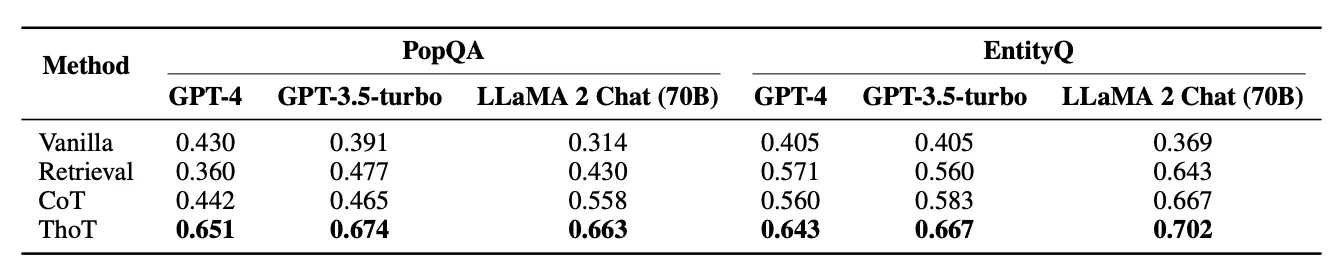
Ergebnisse
Durch die detaillierte Zerlegung des Kontexts entstehen präzisere und Antworten mit weniger Halluzinationen und übertrifft Chain-of-Thought und einfaches Prompting deutlich.
Chain of Note (CoN)
Die Chain of Note-Methode (CoN) ist ein neuer Ansatz, der die Robustheit von Prompts gegenüber irrelevanten oder widersprüchlichen Dokumenten erhöht.
Folgende Probleme von RAG-Systemen werden durch die Chain of Note (CoN) behandelt:
- (1) Risiko der oberflächlichen Verarbeitung: LLMs neigen dazu, sich bei der Formulierung einer Antwort auf oberflächliche Informationen zu stützen, wodurch ein tiefes Verständnis fehlt. Dadurch übersehen die Modelle oft die Feinheiten in Fragen oder Dokumenten übersehen, insbesondere bei komplexen oder indirekten Anfragen.
- (2) Schwierigkeiten bei der Verarbeitung widersprüchlicher Informationen: Die Generierung von Antworten wird besonders schwierig, wenn Dokumente mit widersprüchlichen Daten abgerufen werden. Das Modell muss entscheiden, welche Informationen glaubwürdig oder relevant sind, trotz vorhandener Widersprüche.
- (3) Übermäßige Abhängigkeit von abgerufenen Dokumenten: Die Abhängigkeit von RAG kann dazu führen, dass den inhärenten Wissensspeicher des Modells vernachlässigt wird. Dieses Problem tritt besonders stark auf, wenn mit veralteten oder rauschenden (semantisch ähnliche, aber tatsächlich irrelevante oder inkorrekte Informationen) Dokumenten gearbeitet wird.
CoN arbeitet mit einer schrittweisen Notizenerstellung für jedes abgerufene Dokument, was eine detaillierte Bewertung der Relevanz ermöglicht. Durch die systematische Erstellung von Notizen wird sichergestellt, dass die Modellantwort auf der verlässlichsten verfügbaren Information basiert - und das ohne oberflächliche Verarbeitung oder Übergewichtung irrelevanter Inhalte.

Wie funktioniert CoN?
Fordere das Modell auf, zu jedem abgerufenen Dokument eine kurze Notiz zu erstellen, die die Relevanz bewertet. Z.B. "Erstelle für jedes der abgerufenen Dokumente eine kurze Zusammenfassung und bewerte, wie relevant es für die gestellte Frage ist."

Ergebnisse
Durch die Bewertung der Relevanz von Dokumenten wird die Qualität der Antworten erhöht und Halluzinationen werden reduziert. RAG, das mit CoN erweitert wurde, übertrifft das Standard-RAG durchgängig, insbesondere in Szenarien mit ausschließlich rauschenden Dokumenten. Bemerkenswert ist, dass sowohl das Standard-RAG als auch CoN bei vollständig rauschenden Dokumenten schlechter abschnitten als das ursprüngliche LLaMa-2 ohne zusätzliches Information Retrieval. Diese Beobachtung zeigt, dass RAG durch rauschende Informationen irregeführt werden kann, was zu mehr Halluzinationen führt!

Chain of Verification (CoVe)
Bislang ging es um Techniken, die Argumentation verbessern, bevor eine finale Antwort generiert wird. Jetzt schauen wir uns eine weitere Methode an, die einen anderen Ansatz verfolgt, indem sie Verifikation in den Prozess integriert.
Chain-of-Verification (CoVe) beinhaltet das Erstellen von Verifikationsfragen, um die Argumentation des Modells zu verbessern und seine erste Entwurfsantwort zu bewerten. Das Modell geht diese Fragen dann systematisch durch, um eine optimierte und überarbeitete Antwort zu erstellen. Unabhängige Verifikationsfragen liefern in der Regel genauere Fakten als die im ursprünglichen Langtext enthaltenen Informationen, was die Gesamtgenauigkeit der Antwort steigert.
Wie funktioniert CoVe?
Bei dieser Prompting Methode wird die Antwort verbessert, indem das Modell folgende Schritte durchführt:
- (1) Generierung einer Baseline-Antwort: Als Antwort auf eine gegebene Anfrage generiert das Modell eine Ausgangsantwort.
- (2) Verifikationsplanung: Unter Berücksichtigung der Anfrage und der Baseline-Antwort wird eine Liste von Verifikationsfragen erstellt. Diese Fragen sollen eine Selbstanalyse ermöglichen und mögliche Fehler in der ursprünglichen Antwort identifizieren.
- (3) Verifikation: Jede Verifikationsfrage wird systematisch beantwortet, um die ursprüngliche Antwort zu überprüfen und eventuelle Inkonsistenzen oder Fehler zu identifizieren.
- (4) Erstellung der finalen verifizierten Antwort: Basierend auf entdeckten Inkonsistenzen wird, falls nötig, eine überarbeitete Antwort erstellt, die die Ergebnisse des Verifikationsprozesses integriert.

Ergebnisse
In Untersuchungen mit dem Llama 65B Modell konnte gezeigt werden, dass CoVe die Antwortgüte signifikant verbesserte.
Emotion Prompting
Die Technik Emotion Prompting zielt darauf ab, die Leistung großer Sprachmodelle (LLMs) zu verbessern, indem emotionale Stimuli in die Prompts integriert werden. Ziel ist es, die Modelle durch gezielte emotionale Kontextgebung näher an menschliche Problemlösungsansätze heranzuführen, die auf psychologischen und emotionalen Reaktionen beruhen.
Wie funktioniert Emotion Prompting?
Bei dieser Prompting Methode wird ein emotionaler Kontext direkt in die Prompts eingebunden, um die Input Attention bei der Informationsverarbeitung zu verbessern.
Ergebnisse
Emotion Prompting steigert die Leistung in den meisten Fällen deutlich. Das Verfahren übertrifft in vielen Szenarien bestehende Methoden wie CoT und zeigt seine Effektivität bei unterschiedlichen Aufgaben und Modellen. Interessanterweise profitieren größere Modelle wie Vicuna und Llama 2 stärker von EmotionPrompt als kleinere Modelle wie FlanT5-Large. Dies deutet darauf hin, dass größere Modelle emotionalen Kontext besser nutzen können und dadurch leistungsfähiger werden.
Expert Prompting
Die Technik Expert Prompting nutzt Identitätshacks, bei denen das Sprachmodell (LLM) gebeten wird, eine spezifische Expertenrolle anzunehmen, z. B. als "Jurist, der bei einem wichtigen Fall hilft" oder "Steve Jobs, der bei der Produktgestaltung berät". Diese Methode soll die Qualität und Genauigkeit der Antworten steigern, indem das Modell die Perspektive eines Experten annimmt.
Wie funktioniert Expert Prompting?
Expert Prompting basiert auf In-Context Learning, bei dem detaillierte und auf die Aufgabe zugeschnittene Beschreibungen der Expertenidentität automatisch generiert werden. Durch diese Beschreibung kann das Modell spezifischere und kontextuell passendere Antworten geben. Die Methode ist vielseitig und erlaubt die Definition von Expertenidentitäten über verschiedene Fachbereiche hinweg, z. B. ein Ernährungsberater, der Gesundheitstipps gibt, oder ein Physiker, der atomare Strukturen erklärt.

Ergebnisse
Die Ergebnisse zeigen, dass Expert Prompting das Sprachmodell erheblich verbessert, indem es eine Expertenrolle übernimmt. In Tests lieferte das Modell präzisere und qualitativ hochwertigere Antworten, wenn es sich auf diese spezifische Identität einstellte, z. B. als „Experte" in einem bestimmten Bereich.
Durch die Anwendung dieser Technik wurde ein neuer Assistent namens ExpertLLaMA trainiert, der besonders leistungsfähig ist und andere Modelle übertrifft. ExpertLLaMA kommt in seiner Leistung sehr nah an ChatGPT heran und bietet deutlich bessere Antworten als andere Modelle, ohne dass komplizierte Prompt-Methoden erforderlich sind.
Fazit
Mit fortgeschrittenen Prompting-Techniken wie Thread of Thought (ThoT), Chain of Note (CoN), Chain of Verification (CoVe), Emotion Prompting und Expert Prompting lassen sich Halluzinationen in RAG-Systemen gezielt reduzieren. Diese Methoden bieten eine höhere Genauigkeit und Verlässlichkeit als herkömmliche Ansätze und helfen, sicherere LLM-basierte Anwendungen zu entwickeln.
Mehr über RAG und LLM-Techniken lernen?
In unserem AI Productivity Bootcamp lernst du, wie du fortgeschrittene Prompting-Techniken in der Praxis einsetzt und robuste KI-Anwendungen entwickelst.
Zum Bootcamp