Von Benjamin Kaleja · Founder, AI Catalyst
Secure Model Serving
Air-Gap LLM für interne AI Suite im regulierten Umfeld
Unternehmen in regulierten Branchen stehen vor einem Dilemma: Die Fachabteilungen fordern moderne LLM-Fähigkeiten, während Compliance und IT-Security externe Cloud-APIs ausschließen. Die Lösung: Self-Hosted Large Language Models in einer vollständig isolierten Infrastruktur.
Dieser Leitfaden zeigt, wie ein 100B+-Parameter-Modell sicher im eigenen Sicherheits-Perimeter betrieben wird - von der Hardware-Dimensionierung bis zum laufenden Betrieb.

Wann ist ein Air-Gap LLM sinnvoll?
Ein vollständig isoliertes LLM-Setup ist der richtige Ansatz, wenn folgende Anforderungen vorliegen:
- Keine Daten dürfen das Unternehmensnetzwerk verlassen (Data Residency)
- Vollständige Nachvollziehbarkeit aller KI-Interaktionen für Audit-Zwecke
- Integration in bestehende Identity- und Access-Management-Systeme erforderlich
- Regulatorische Vorgaben (EU AI Act, DSGVO, branchenspezifische Compliance)
- Verarbeitung von Daten mit hoher Klassifizierungsstufe
Wenn diese Kriterien nicht zutreffen, sind Cloud-APIs oft die kosteneffizientere Wahl.

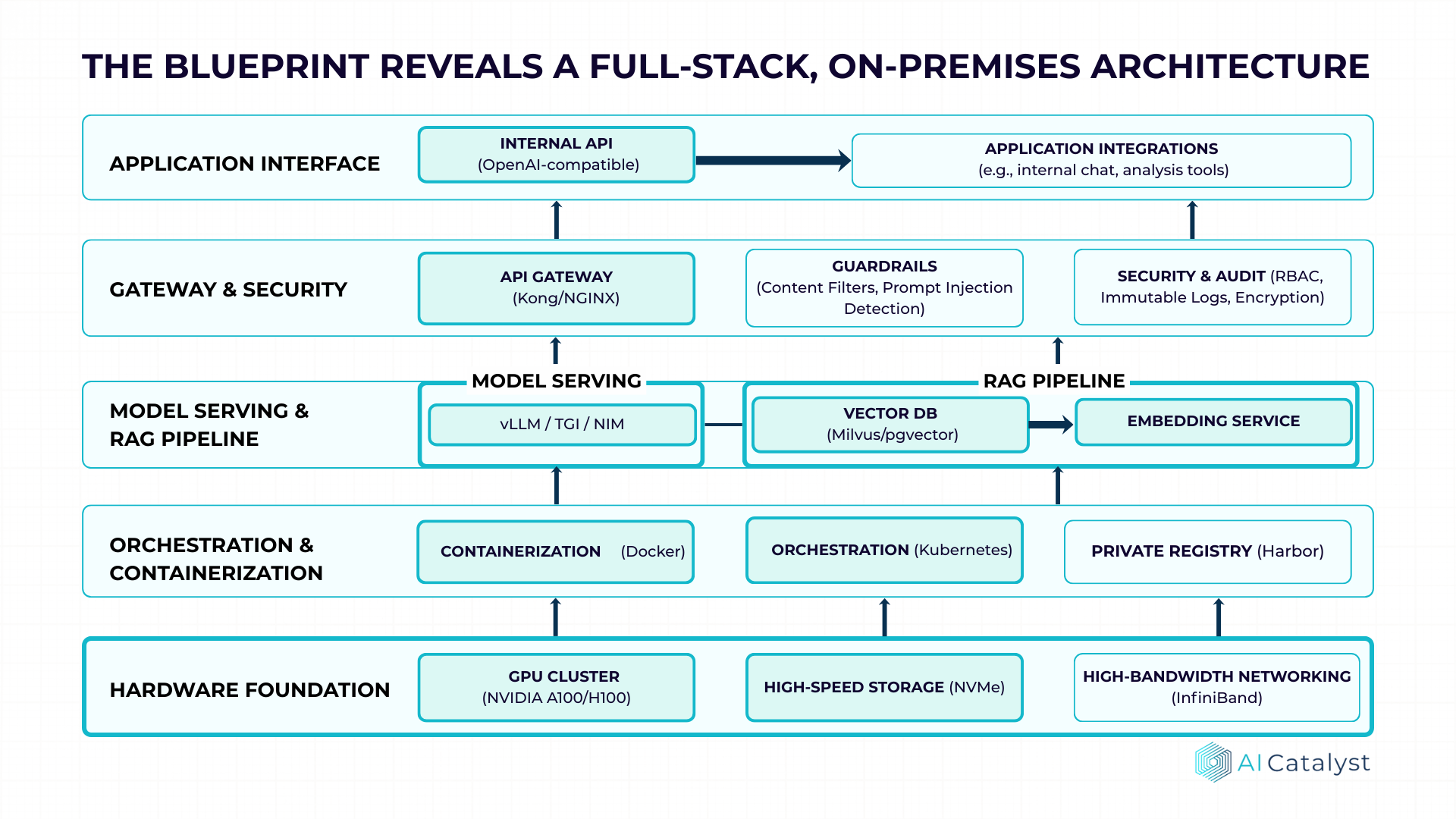
Hardware-Dimensionierung
Für ein 100B+ Parameter-Modell (z.B. Llama 3.1 405B quantisiert oder Llama 3.1 70B in FP16) gelten folgende Richtwerte:
| Komponente | Empfehlung |
|---|---|
| GPU | 4-8x NVIDIA H100/A100 (80GB VRAM) mit NVLink |
| System-RAM | 256-512 GB DDR5 für KV-Cache und Batching |
| Storage | NVMe-Array, 2-5× Modellgröße (für Checkpoints, Quantisierungen) |
| Netzwerk | Dediziertes VLAN, kein Internet-Egress |
💡 Best Practice: GPU-Beschaffung hat Lead-Times von 12+ Wochen. Frühzeitig in den Procurement-Prozess einsteigen und Quantisierungsoptionen (FP8/INT8) evaluieren, denn sie reduzieren Hardware-Anforderungen bei akzeptablem Qualitätsverlust erheblich.
Software-Stack
Ein produktionsreifer LLM-Stack besteht aus mehreren Schichten:
Model Serving Layer
- •vLLM oder TGI als Inference-Engine mit Tensor-Parallelismus
- •OpenAI-kompatible API für einfache Integration bestehender Tools
- •Batching und KV-Cache-Optimierung für maximalen Durchsatz
RAG-Pipeline
- •Vektor-Datenbank: Milvus, pgvector oder Qdrant
- •Embedding-Service: E5-Large, BGE oder sentence-transformers
- •Document Loader: Anbindung an DMS, SharePoint, Confluence etc.
Gateway & Observability
- •API Gateway: Kong, NGINX oder Envoy mit OIDC-Integration
- •Monitoring: Prometheus/Grafana für GPU-Utilization, Latenz, Throughput
- •Logging: Strukturiertes Request-Logging, SIEM-Integration
Guardrails
- •Content-Filter: Toxicity-Detection, PII-Masking
- •Prompt-Injection-Detection: Llama Guard oder regelbasierte Filter
- •Output-Validation: Schema-Checks für strukturierte Responses
Security muss von Anfang an designbestimmend sein:
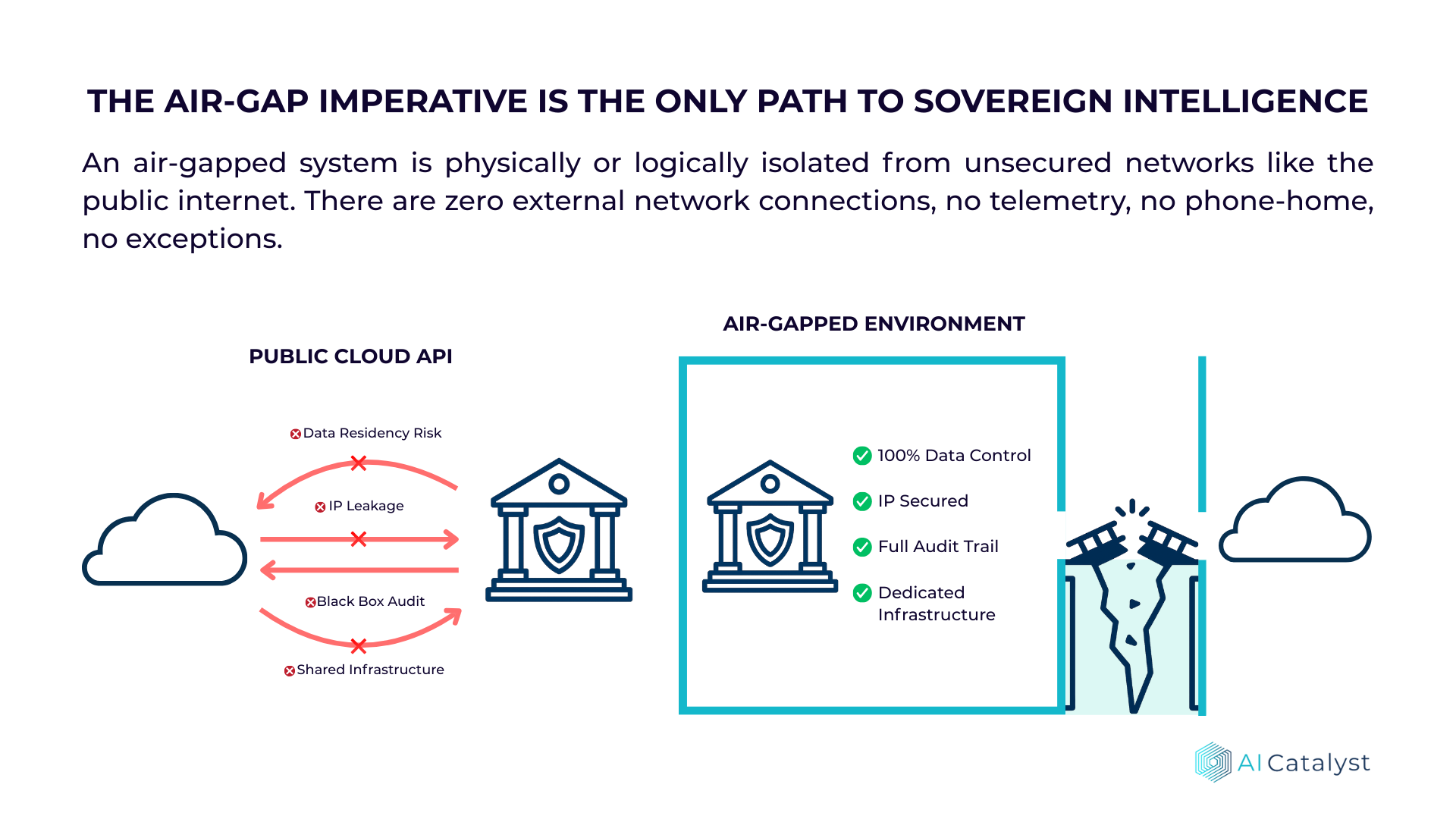
Netzwerk-Isolation
- •Air-Gap: Kein Egress vom LLM-Segment ins Internet
- •Dediziertes VLAN: Nur definierte interne Subnets dürfen zugreifen
- •Modell-Updates: Manueller, geprüfter Transfer über Bastion-Host
Identity & Access
- •Zero-Trust: Jeder API-Call authentifiziert über unternehmensweites IdP
- •Service-to-Service: mTLS zwischen allen Komponenten
- •RBAC: Feingranulare Berechtigungen pro Endpoint und Modell
Audit & Compliance
- •Audit-Trail: Vollständiges Logging aller Prompts/Responses (ggf. anonymisiert)
- •Retention: Konfigurierbar nach Compliance-Vorgaben (z.B. 90 Tage)
- •Container-Hardening: Non-Root, Read-Only-FS, regelmäßige CVE-Scans
Implementierung in 5 Phasen
Phase 1: Discovery & Requirements
Use Cases priorisieren, Success Metrics definieren (Latenz, Verfügbarkeit, Durchsatz). Infrastruktur-Assessment: Welche GPU/CPU-Ressourcen sind verfügbar? Wie sieht die Netzwerk- und Security-Architektur aus?
Phase 2: Solution Design
Zielarchitektur mit Plattform-Team abstimmen. Hardware-Sizing basierend auf Concurrency-Annahmen. Bill of Materials erstellen: Hardware-SKUs, Container-Stack, Observability-Tools.
Phase 3: Implementation
Infrastruktur im Dev/Test-Environment aufbauen. Integration mit Identity-Stack, Logging, Monitoring. LLM-Serving-Layer und RAG-Pipeline deployen.
Phase 4: Testing & Hardening
Load-Tests bis 2× erwartete Peak-Last. Security-Assessment inkl. Penetration-Test. Red-Teaming für Prompt-Injection und Jailbreak-Versuche.
Phase 5: Rollout & Operations
Pilotierung mit Power-Usern, iterative Erweiterung. Runbook-Dokumentation und Wissenstransfer. Continuous Improvement: Modell-Updates, Prompt-Tuning, neue Use Cases.
Praxis-Tipps
Häufiger Fehler: Blind das größte Modell deployen. Nicht jeder Use Case braucht 100B Parameter. Ein Routing-Layer zu kleineren spezialisierten Modellen (7B-70B) optimiert Kosten und Latenz erheblich.
- •Quantisierung evaluieren: FP8/INT8 reduziert VRAM-Bedarf um 50%+ bei oft <5% Qualitätsverlust. Für jeden Use Case separat testen.
- •RAG früh testen: Chunking-Strategie und Embedding-Modell haben massiven Einfluss auf Antwortqualität. Iteratives Tuning einplanen.
- •Ops-Ownership klären: Vor Go-Live festlegen, wer den Stack betreibt. Knowledge Transfer ist kritisch für nachhaltige Adoption.
- •Latenz-Budget verstehen: Token-Generation ist sequenziell. Bei langen Outputs (>500 Tokens) wird Streaming zur UX-Pflicht.
- •Failover planen: GPU-Ausfälle passieren. Redundanz oder klare RTO/RPO-Definitionen sind Pflicht für produktionskritische Systeme.
Zielmetriken
Realistische Benchmarks für ein gut konfiguriertes On-Prem-Setup:
| Metrik | Zielwert |
|---|---|
| Time to First Token (p95) | < 500ms |
| End-to-End Latenz (p95) | < 3 Sekunden (bei ~200 Output-Tokens) |
| Verfügbarkeit | 99.5%+ (mit Redundanz: 99.9%) |
| Concurrent Users | 50-200 (je nach Hardware-Sizing) |
Fazit
Self-Hosted LLMs im Air-Gap-Modus sind keine Rocket Science mehr. Mit den richtigen Architekturentscheidungen und einem strukturierten Vorgehen lässt sich ein Enterprise-Grade-System in 3 bis 4 Monaten produktiv bringen.
Der Schlüssel: Nicht blind das größte Modell deployen, sondern Use Cases, Hardware-Constraints und Betriebsmodell gemeinsam denken. Die Komplexität ist beherrschbar - wenn man sie von Anfang an einplant.
Sie planen ein Air-Gap-LLM-Projekt?
AI Catalyst unterstützt bei Konzeption, Implementierung und Betrieb sicherer On-Prem-LLM-Architekturen - von der Hardware-Auswahl bis zum Production Readiness Review.
Beratungsgespräch vereinbaren